

- データサイエンティストが語るVol.1
製造業のデータ活用はなぜ難しい?現場で使える解決策と実践ノウハウを公開
製造業においてデータの活用が重要視されてから久しい。どの工場でヒアリングをしても「データの活用はある程度進んでいる」という回答が返ってくる。この微妙な答えには、満足はできていないというニュアンスが含まれている。そこにはどんな課題があるのか?このブログでは、製造現場とソフトウェア販売の両方の立場で長年データ活用をしてきたデータサイエンティストがその課題と解決方法について解説する。

データ活用の2つの分類
データ活用に満足ができていない理由は、データ活用を下のような2つに分類した時に、「蓄積されたデータの活用」の期待と難易度が高く、そこに満足していないからだ。
分類 | 目的 |
ダッシュボードによる現状把握 | ダッシュボード等を活用し、生産数などの重点項目の現状把握をする。変動を検知した場合はその情報を共有し、早急なアクションに結びつける。 |
蓄積されたデータの活用 | 表計算ソフト、統計解析ツール、機械学習などを駆使し、膨大なデータから知見を得ること。 |
どの工場でも、データ活用の第一歩はデータの取得、電子化、そして「ダッシュボードによる現況把握」になる。それは間違っていないし、それで十分な工場も存在する。
しかし、蓄積されたデータの活用となると、まったく別の議論が必要となる。もしかしたら、せっかく構築したデータ取得の仕組みを大幅に変更する必要が出てくるかもしれない。これまでかけたコストや工数が無駄になると思うと躊躇するのも当然だ。ダッシュボードまでできているならば、手をつけたくないことなのかもしれない。
将来的に蓄積されたデータの活用(例えば予兆検知など)まで視野に入れるのであれば、その時に何が起きるのか?何が必要だったのか?をできるだけ早く知っておきたいところだ。
要因分析は共通の技術
「蓄積されたデータの活用」の代表例は、工場内で不良が発生した時の「データを活用した」原因追及だ。呼び方は沢山あるが、ここでは要因分析という呼び方に統一する。
工場勤務者以外にはピンと来ないかもしれないが、どのような製品も最終的には何らかの検査が行われ、日々不良が発生している。化学変化を伴うプロセス系の工場であれば、不良率は高く、化学変化を伴わない組立て系の工場では不良率は低い傾向はあるが、組立て系であってもその部品はプロセス系の工場で作られていることを考えれば、どの工場も日々発生している不良と対峙している。
製造している製品や工場が異なれば要因分析の方法も異なる印象はある。しかし、どのような製品であっても、不良が発生すれば、対策や改善が求められる。そのためには不良の発生した工程や装置などを見つける必要があり、その方法は汎用化された共通の技術となる。
要因分析に必要なデータ
どんな工場にも当て嵌まる汎用化された要因分析の技術を説明する前に、使用されるデータについての説明が必要だ。このブログでは、工場内で取得されるデータを3つに分類する。
分類 | データの種類 |
結果系データ | 各種検査データ。 |
要因系データ | 検査データの変動の要因を示すデータ。 |
製品履歴データ | 各製品の処理履歴を示すデータ。 |
要因分析のフロー
ステップ0:要因分析のスタート、不良率のトレンド
要因分析のスタートは、下のように最終検査日時をX軸とした不良率のトレンドを見て、不良率が増加していることに気が付いたところからスタートすることが一般的だ。この時点で要因分析をしても不良となった製品が良品に生まれ変わることもないし、その後に続く製品も既に不良になっている「It’s too late (時すでに遅し)」の可能性もあるが、できるだけ早急に要因分析を開始しないといけない。
↓クリックで図版を拡大
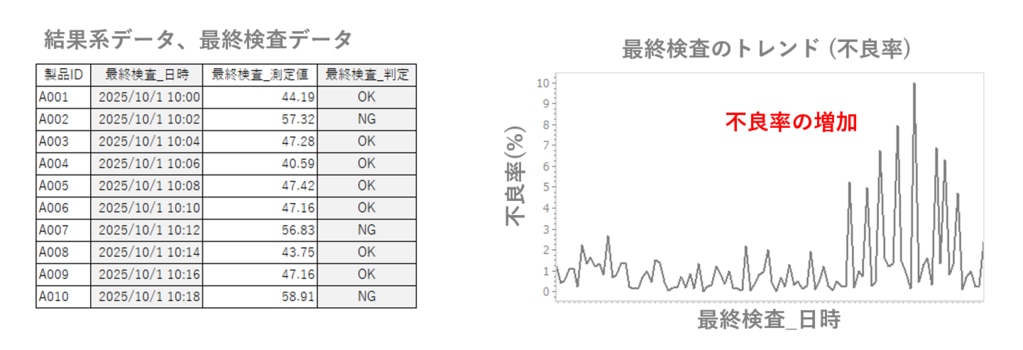
このトレンドで注意が必要なのは、最終検査データというのは、上の表のように各製品IDについて、測定値が取得されており、最終検査判定が行われているにも関わらず、そこから不良個数を合計して、何らかの母数で割った不良率(割合)にしていることだ。母数の例は、1日単位の生産量、交代勤務単位の生産量、または同じ品種でグループ化されたロット単位だったりする。割り算にしている理由は、不良率を見た人間が相対的に判断しやすいことだ。同じ母数の不良率にしておけば、品種が沢山あっても比較しやすく、過去との比較もしやすい。
しかしながら、要因分析ではこの相対的な判断(つまり不良率への変換)は、全く意味がない。要因分析は個々の製品に対して原因を追究することを目標とするので、割合にしてしまうと、個々の製品についての情報が失われてしまう。よって、不良率のトレンドがあったとしても、上の最終検査データのように、個々の製品について、測定値や判定結果の情報を再度入手することが必要となる。工場によっては、不良率だけが保存されており、製品IDごとの測定値は保存されていない場合もあり、最初のハードルとなってしまう場合もある。
もう1つ注意する必要があるのは、不良率トレンドのX軸は、最終検査の日時となっている点だ。最終検査の日時は、あくまで検査をした日時であって、不良が発生した日時ではないので、このトレンドの不良率の並び順に殆ど意味はない。
要因分析では、「不良が発生したら、しばらく不良が連続する」という前提が必要になる。不良の原因が原料であれば、その原料が続く限り不良となり、不良の原因が装置の故障や異常であれば、その装置は連続して不良を作り続ける。つまりは、不良が発生した工程の日時で並べると、異常な測定値は連続するはずだ。この最終検査のデータには、不良が発生した工程の情報はないので、次のステップに進むことにする。
ステップ1:結果系データの分析
このステップでは、前のステップで説明した「不良が発生したら、しばらく不良が連続する」という前提について、データで表現する。
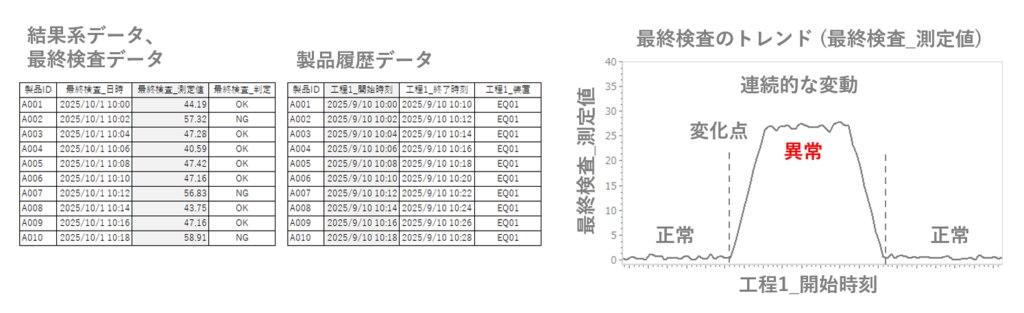
最初に最終検査データと要因系データの1つである製品履歴データを製品IDなどで紐付けて、工程ごとの開始時刻、終了時刻、使用装置の情報を得る。そして、下のように工程の開始時刻をX軸、最終検査の測定値をY軸としたトレンドチャートを描画してみる。
このようなトレンドチャートを描いた時に、上記の前提が成り立つのであれば、正常と異常の境目には、変化点を見つけることができるはずだ。逆に言えば、この変化点が見つかり、正常と異常の差異が明確になる工程が、不良発生の工程と推定できる。工程の数が多い場合、偶然に同じようなグラフになることもあるが、これにて不良発生の工程が絞り込まれたことになる。
このステップの名前を「結果系データの解析」とした理由は、このような結果系データを工程の時刻順に並べた時に変化点が明確になることは稀であり、多くの場合、結果系データである最終検査の測定値を加工する必要があるからだ。分かりやすい例は、測定値にはノイズが多く、そのままでは変化点が見つからない場合だ。このような時は、移動平均値に変換するなどをして平滑化を行い、変化点を明確にする必要がある。この方法には明確な決まり事がなく、データの分布や製品の特徴を考慮した解析(トライ&エラー)が必要となってくる。この解析は重要で、ここで手を抜くと何も見つからない可能性が高い。
↓クリックで図版を拡大
ステップ2:要因系データとの紐付け
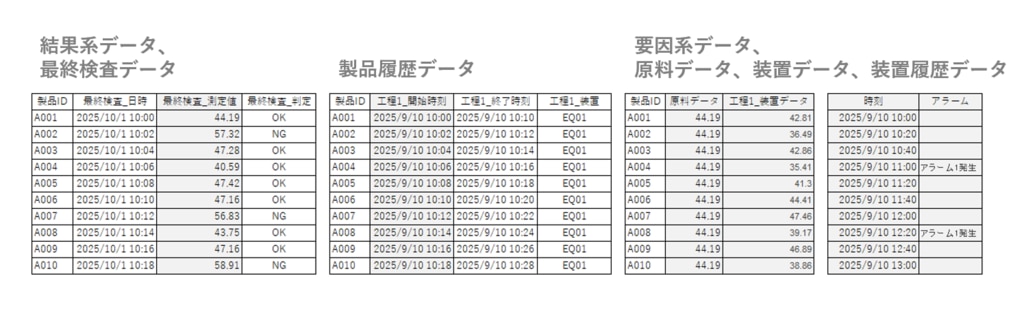
前のステップで不良が発生した工程が推定されたとする。次に行うことは、下のように、製品IDをキーとして、要因系データである、原料データ、装置データ、装置履歴データを取得することだ。ここでは工程が推定された前提で、工程1だけの装置データなどを取得しているが、他の工程の装置データをまとめて取得しても良い。このステップで次の可視化に必要なデータは全て揃ったことになる。
↓クリックで図版を拡大
ステップ3:要因系データと結果系データの可視化
ステップ2でデータの準備が終わり、ここからは可視化を行う。機械学習を活用する場合もあるが、このコラムでは基本的な方法として、可視化の方法を説明する。
可視化の1番手はトレンド解析だ。先ほどの変化点を検知したトレンドチャートに、装置履歴データから取得したイベント(アラームなど)を同時に描画してみる。変化点の発生、つまり不良の発生は、アラーム1の発生と同タイミングとなっており、装置の異常によってアラームが発生し、不良の発生原因となったという仮説が立てられる。
トレンド解析のもう1つの方法は、同じ変化点のトレンドに装置データを重ね合わせて描画してみることだ。装置データが測定値と同じタイミングで変化していれば、装置の異常によって装置データが変動し、不良の発生原因となったという仮説が立てられる。
↓クリックで図版を拡大

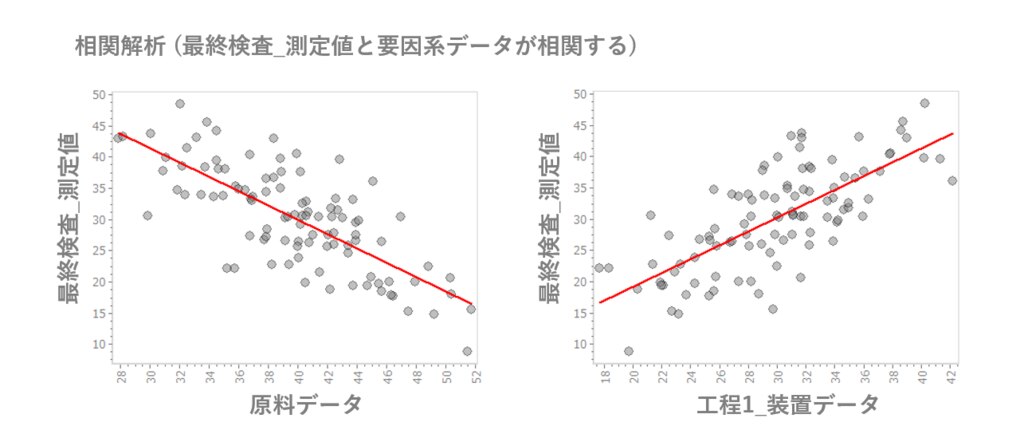
可視化の2番手は相関解析だ。近年では原料や装置のデータは安定しているので、下のように単純な相関関係が見られることは稀であるが、必ず試しておく必要がある。
またこのような散布図による相関解析では、装置IDや作業員などで層別することで相関関係が明確になるケースもあるので、層別できるかどうか?は必ず確認する必要がある。
↓クリックで図版を拡大
最後はドメイン知識による結果の解釈
ここまでのトレンド解析や相関解析で結果系データである最終検査の測定値と要因系データである装置からのアラームなどのイベントや装置データ、原料データとの関係性が見られたとしても、要因分析はここで終わりではない。あくまで仮説が構築できたに過ぎない。
最後にはドメイン知識による結果の解釈が必要となる。ドメイン知識とは、工場の運用方法、製品の作り方、物理現象、化学現象と多岐に及ぶが、これらの理屈とデータ解析の結果を紐づける必要がある。それができてやっと、「この不良の原因は、装置の○○に異常が発生したからです。それがデータとして○○に現れています。」と結論付けることができる。
実際はそんな簡単ではない?
ここまで要因分析のステップを解説してきたが、実際に要因分析を行っている担当者からは「そんな簡単ではない」「失敗して、何も見つからない時もある」という声が聞こえてきそうだ。そうならば具体的には何が課題なのか?考えられるのは下の3つの項目だ。
項目 | ポイント |
データ | 必要なデータが必要な粒度で揃っていること、など。 |
データ活用基盤 | 蓄積されたデータとデータ前処理、可視化などのツールがシームレスに連携していること、など。 |
データ解析スキル | 工場や製品に対するドメイン知識、統計解析、機械学習の知識が備わっていること、など。 |
✅データサイエンティストが語るVol.1のPDFはこちら>>
次回のブログ(公開準備中)
データ、データ活用基盤、データ解析スキルについて、具体的なニーズ、あるべき姿、課題、解決策を解説する。
YDC SONARのご紹介
フューチャーアーティザン株式会社が提供するYDC SONARは、製造業のデータ活用基盤として多くの実績を持つソフトウェアです。今回のような複雑なステップが必要な解析をスムーズに行うことができます。詳細は以下のサイトから資料をダウンロードできます。

・ ○○ができていない○○ができていない
・ ○○を改善したい○○を改善したい
・ ○○に不満を感じている○○に不満を感じている





